[Deep Learning] 문자인식의 성능지표
문자인식의 성능지표
본 포스팅은 2019진행된 네이버 개발자 컨퍼런스에서 발표된 “문자인식(OCR), 얼마나 정확하지? (문자인식 성능을 정확하게 측정하는 방법)”에 대한 내용을 정리한 글입니다. https://tv.naver.com/v/11210453
1 성능 평가의 중요성
1) 성능 개선
- 성능을 알아야, 문제점을 파악할 수있고, 성능을 개선할 수 있기때문에 중요합니다.
2) 모델 선택
- 다양한 아키텍처가 제안되고 있는데 어떤 모델을 적용할 것인지 성능을 평가, 비교하여 선정합니다.
3) 다른 연구 그룹과의 성능 비교
- ImageNet대회에서 딥러닝 모델이 상위랭크에 오르며 딥러닝 기술이 발전한 것과 같이 다른 연구 그룹과의 선의의 경쟁을 통해 기술이 진보되므로 다른 그룹과의 성능 비교가 가능해야 합니다.
2 성능 평가 방법
1) 사람이 직접 평가
- 시간과 비용이 많이 들고, 평가에 오류가 있을 수 있습니다.
- 같은 문제에 대해 평가자들에 따라 다른 결과를 도출해낼 수도 있습니다.
2) 자동 평가 시스템
- 시간과 비용이 거의 들지 않으며, 평가에 오류가 없습니다.
- OCR은 다른 분야보다 평가기준이 명확한 편에 속합니다.
3 문자인식(Optical Character Recognition)
- 오프라인의 글자를 기계가 읽을 수 있도록 디지털한 것
1) 문자인식 응용분야
- 자동차 번호판/명함/신용카드/신분증 인식, 이미지 번역
2) 문자인식 과정
- 문자 검출(Text Detection) -> 문자 인식(Text Recognition)
3) 기존 평가 방법
- 문자 검출의 평가방법
- IoU(Intersection over Union)
- 정답(Ground Truth)과 예측(Prediction) 박스가 얼마나 겹치는지 확인(50% 기준)
- IoU(Intersection over Union)
-
문자 인식의 평가방법
- WEM(Word based Exactly Matching)
- 정답과 예측 단어가 정확히 일치하는지 체크(단어기반)
- 글자 1개라도 틀리면 0점이고, 글자 모두 일치해야 100점

- 1-NED
- 두 단어간 편집 거리(삽입, 교환, 삭제)를 측정한 뒤, 긴 단어의 길이로 정규화(글자기반)
- 점수 = 1-1/전체 글자의 길이

- WEM(Word based Exactly Matching)
-
문자 검출과 문자 인식 모두의 평가 방법
- End to End(검출 + 인식) 평가 방법
- 검출과 인식을 같이 평가
- 순차(Cascade) 평가 처리 : 검출 평가(IoU) -> 인식 평가(WEM, 1-NED)
- $Recall=\frac{맞춘 단어의 수}{정답 단어 수}$
- $Precision=\frac{맞춘 단어의 수}{예측 단어 수}$
- End to End(검출 + 인식) 평가 방법

4 기존 평가의 문제점
1) 정교한 성능 측정 불가(부정확성)
- 글자가 하나만 빠져도 겹치는 영역의 IoU점수가 50%이상이면 Positive 처리를 하는데 사실은 False Positive 처리를 해야하는 것이 맞습니다

- 곡선형태의 문자영역을 잘 취득했지만 IoU점수가 50%이하라는 이유로 Negative 로 판정했는데 사실은 False Negative가 맞습니다

2) One-to-Many 문제
- 하나의 정답 박스가 여러개의 박스로 나뉘어 예측되는 경우가 있습니다.
- RIVERSIDE를 RIVER 와 SIDE 두개의 단어로 나누어지면서 IoU점수가 50%이하로 False Negative 판정에 의해 0점 처리됩니다.

3) Many-to-One 문제
- 여러개의 정답 박스가 한개의 박스로 합쳐져 예측되는 경우도 발생합니다.
- One-to-Many와 반대로 SURF와 LIFE로 예측하길 바랐지만 SURFLIFE로 예측하는 경우에도 IoU점수가 50%이하로 False Negative 판정으로 0점 처리됩니다.

4) End to End(검출+인식) 평가 방법의 문제
-
검출 평가후에 인식을 평가함으로 인해 오류가 전파됨
-
One to Many 문제로 인해 RIVERSIDE 가 RIVER 와 SIDE 두개의 단어로 나누어짐
SIDE 라는 단어는 탐지평가에서 0점을 받아 인식평가를 받지도 못하게 되어버림

5. 신규 방법의 고려사항
- End-To-End(검출+인식) 평가
- 사람처럼 검출과 인식을 동시게 평가해야 함
- One-to-Many, Many-to-One대응 가능해야 함
- 객체 검출과 달리 문자 인식에서는 자주 발생
- 개별 글자 단위로 평가
- 정교하게 그리고 세부적으로 성능 측정이 가능해야 함
-
기존 평가셋과 호환되어야 함
-
단어 단위의 평가셋에서도 잘 동작해야 함
-
(글자 단위의 평가셋은 거의 없으며, 새로 만들기 어려움)
-
6. 신규 방법 소개
1) 기본 처리방식

- 다음과 같은 GT와 Pred에 대해 어떻게 평가하는지 보겠습니다
- GT : DEVIEW2019
- Pred : VIEVV201
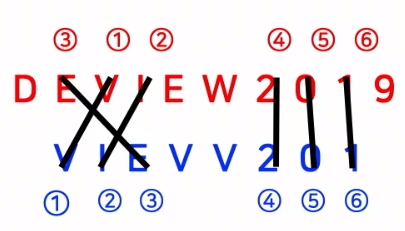
- GT와 Pred 에서 단순히 겹치는 글자의 개수를 셉니다
- Pred 의 E의 경우 GT의 D 와 V사이의 E 와 I와 W 사이의 E 가 있는데 가장 앞에 있는 D와 V 사이의 E로 비교합니다
-
$Recall=\frac{맞춘 글자 수}{정답 글자수}=\frac{6}{len(DEVIEW2019)}$ 이 됩니다
- $Precision=\frac{맞춘 글자 수}{예측 글자수}=\frac{6}{len(VIEVV201)}$ 이 됩니다
2) One-to-Many 문제 처리

- 겹치는 영역의 글자 중에서, 같은 글자(맞춘 글자)를 하나씩 지워나간다
- GT : DEVIEW2019
- Pred :
- DEVIEW
- 2019
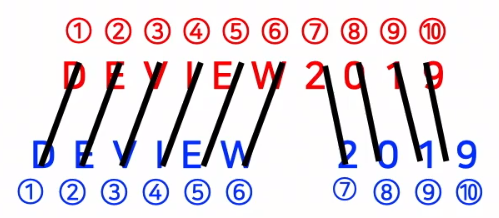
-
$Recall=\frac{맞춘 글자 수}{정답 글자수}=\frac{10}{len(DEVIEW2019)}$ 이 됩니다.
-
$Precision=\frac{맞춘 글자 수}{예측 글자수}=\frac{10}{len(DEVIEW2019)}$ 이 됩니다.
3) Many-to-One 문제 처리

- 겹치는 영역의 글자 중에서, 같은 글자를 하나씩 지워나간다
- GT :
- DEVIEW
- 2019
- Pred :
- DEVIEW2019
-
$Recall=\frac{맞춘 글자 수}{정답 글자수}=\frac{10}{len(DEVIEW2019)}$ 이 됩니다.
-
$Precision=\frac{맞춘 글자 수}{예측 글자수}=\frac{10}{len(DEVIEW2019)}$ 이 됩니다.
4) 엣지 케이스
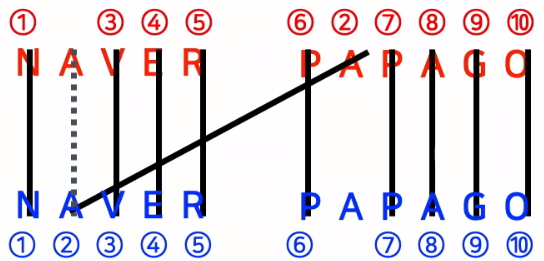
- 제거해야할 글자가 중복될 경우 어떤 글자부테 제거해야할까?

- GT :
- NAVER
- PAPAGO
- Pred :
- NAVER
- PAPAGO
- One-to-One관계의 박스부터 우선 처리
- pred의 NAVER는 GT의 NAVER와 PAPAGO하고 겹치지만 pred의 PAPAGO는 GT의 NAVER하고만 겹치므로 One-to-One 관계의 pred PAPAGO 먼저 처리합니다.
- Many to One 관계에서는 교집합 영역이 클수록 우선 처리합니다.
6. 신규 방법 검증
1) 실험 환경
- 데이터 셋
- ICT13
- ICT15
- 예측 모델 :
- 검출기 : EAST, PixelLink
- 인식기 : GRCNN, ASTER
2) 검증 실험결과
-
One-to-Many와 Many-to-One 문제는 얼마나 발생하나?
-
이 문제들이 실제 많이 발생하면 신규방법은 사용할 수 없음
👉 전체 박스의 2~9%에 해당하며, 이는 리더보드 Top10 내 순위에 영향을 주는 유의미한 수치임
-
-
기존 평가셋과 호환 가능한가?
-
다른 연구그룹에서도 사용가능해야 하므로 단어 단위의 평가셋과 호환이 가능해야함
👉 단어 단위의 평가셋과 글자 단위의 평가셋의 성능 차이가 크지 않아 호환이 가능할 정도였음
-
-
신규 평가 방법은 믿을만 한가?(신규 평가 방법에 대한 평가)
- 3명의 평가자 모집, 기존 방법과 신규 방법에 대한 점수 부여
-
IC13과 IC15의 모든 데이터셋 이용하여 꽤 많은 평가기준적용하였음
👉 피어슨 통계 분석 결과, 기존의 평가방법보다 신규 평가방법이 더 우수했으며, 신규방법의 단어 단위와 글자 단위간의 차이는 적었음
7.앞으로의 과제
- 글자의 Permutation문제
- 단어 단위에서 개별 글자의 순서가 뒤바뀌는 경우가 존재하는데 이에 대해 100점 처리를 하고 있음
- 실제 데이터셋에서 얼마나 발생하는지 확인해본 결과 3000개의 문자 박스에서 1~2개 발생하고 있음
- 예를 들어 MORTDECAI 라는 단어에 대해 MORIDECAT 단어로 인식이 되었는데 문자가 뒤바뀐 것이아니라 I가 T처럼 보이고 T가 I 처럼 인식되서 발생한 문제임

- 띄어쓰기 가 있는 경우에 대해서는 아직 대응을 못하고 있어서 다음 연구과제로 생각중임
Leave a comment